Download S3 Files From R
Making Sense of Big Data
R Shiny — Enable Efficient File Downloads from Amazon S3
Learn how to enable efficient file downloads on R Shiny using Amazon S3 signed URLs.
![]()
Although there are some excellent packages available in the R universe to work with S3 from R, and even though all these packages can easily be integrated with R Shiny seamlessly, I still face some interesting challenges when working with large files through R shiny. Let's start by asking ourselves a simple question.
How do we access the files from an S3 bucket to perform data analysis?
Accessing S3 data from R
Accessing S3 data from R could never be easier, thanks to the packages at our disposal.
The aws.s3 package contains pow e rful functions that integrate with the S3 REST API, which allows the user to manage their S3 bucket programmatically. From personal experience, the documentation, usability, and readability of the codebase are excellent.
I'm not going to delve deep into how to use the package, but let's explore what happens when we attempt to get data from an S3 bucket.
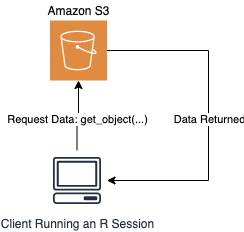
The get_object("my_bucket") function call makes a request to S3. The function handles authentication under the hood, and finally, the requested data is returned to the client.
The workflow described above is best suited for performing exploratory work locally because the data is transferred, as you would expect, across the network from S3 into your local machine.
However, using this methodology in R Shiny is no longer the most efficient approach because our code is no longer the "client."
Accessing S3 data from R Shiny
When working with R Shiny, it is essential to remember that the code we write is executed on either the instance or the worker spun up by the shiny-server. The client is now the end-user who is actually connecting to and using our application.
The workflow described above works from within a shiny application; however, we are now presented with two potential use cases.
- Get data from S3, use this data within the shiny app or perform some analysis, and present the data in a visualization.
- Deliver the data directly to the user in the form of a data download.
Use case #1 — query, consume and present S3 data
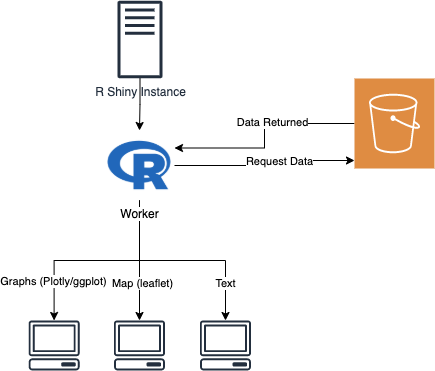
In the workflow described in the diagram above, the goal is to
- Get data from S3.
- Consume the data from within
server(...)to do some useful work. - Present the data in the form of a visualization. (Optional)
To achieve this, we can re-use the code presented above. An example of this, sans the data visualization code, is presented in the code excerpt below.
Use case #2 — deliver direct data download
The naive approach
If we were to use the previous methodology to deliver the data as a direct data download, it would present us with a new problem. Here is what the code and workflow would look like.
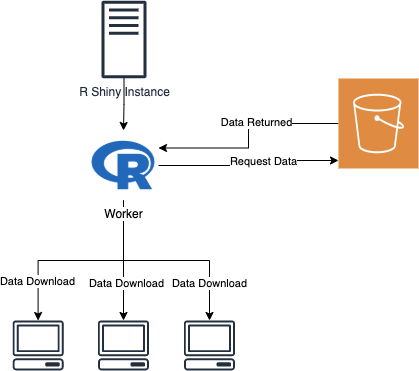
Looking at the diagram and code above, we can start to spot the inefficiencies in the process. The worker process first requests data. Then, once the data is returned over the network, it is written to the client's file system. The data has two trips over the network. If we could half this, that would greatly improve the efficiency of our system.
Authorized signatures
Authorized signatures allow R Shiny to generate a temporary URL that the client can use to access data. This URL enables the client to download the data directly from an S3 bucket, essentially bypassing all intermediate steps. This cuts the network data transfer in half and provides a large boost in download times.
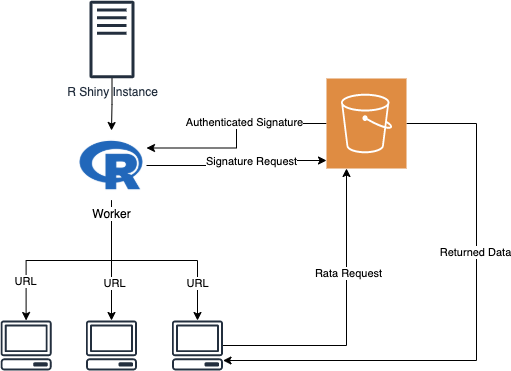
How to generate authenticated URLs
While using signatures to generate authenticated URLs isn't a novel approach, as far as I know, the packages currently available in R certainly don't provide an easy way to achieve this. I developed a helper function with the help of the official Amazon AWS documentation and the internal workings of aws.s3 to generate the authenticated URLs.
Using this helper function, the Shiny code to download a file from S3 would look like the following.
Summary
In the examples presented above, when presenting the client with a data download, taking the naive approach of querying the data from within Shiny using aws.s3 is a suboptimal approach. A more efficient method is to generate a signature using aws.signature and then use it to generate a signed URL. The client can then use the signed URL to download the data directly.
For future work, it will be useful to get this functionality incorporated into aws.s3 . That way, the package will be a step closer to becoming a one-stop-shop for all things S3 related in R and R Shiny.
Posted by: gamecubees.blogspot.com
Source: https://towardsdatascience.com/r-shiny-enable-efficient-file-downloads-from-amazon-s3-f575bfb21244